SQL
![]()
Open In Colab
Use case
Enterprise data is often stored in SQL databases.
LLMs make it possible to interact with SQL databases using natural language.
LangChain offers SQL Chains and Agents to build and run SQL queries based on natural language prompts.
These are compatible with any SQL dialect supported by SQLAlchemy (e.g., MySQL, PostgreSQL, Oracle SQL, Databricks, SQLite).
They enable use cases such as:
- Generating queries that will be run based on natural language questions
- Creating chatbots that can answer questions based on database data
- Building custom dashboards based on insights a user wants to analyze
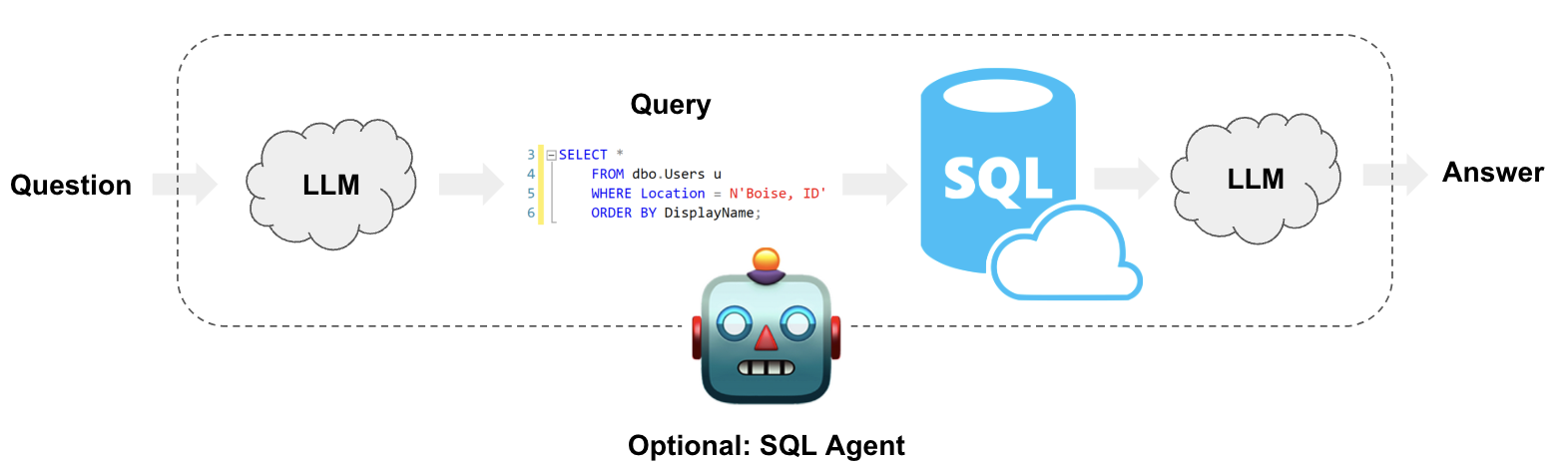
Overview
LangChain provides tools to interact with SQL Databases:
Build SQL queriesbased on natural language user questionsQuery a SQL databaseusing chains for query creation and executionInteract with a SQL databaseusing agents for robust and flexible querying
Quickstart
First, get required packages and set environment variables:
! pip install langchain langchain-experimental openai
# Set env var OPENAI_API_KEY or load from a .env file
# import dotenv
# dotenv.load_dotenv()
The below example will use a SQLite connection with Chinook database.
Follow installation
steps to create
Chinook.db in the same directory as this notebook:
- Save this
file
to the directory as
Chinook_Sqlite.sql - Run
sqlite3 Chinook.db - Run
.read Chinook_Sqlite.sql - Test
SELECT * FROM Artist LIMIT 10;
Now, Chinhook.db is in our directory.
Let’s create a SQLDatabaseChain to create and execute SQL queries.
from langchain_community.utilities import SQLDatabase
from langchain_experimental.sql import SQLDatabaseChain
from langchain_openai import OpenAI
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
db_chain.run("How many employees are there?")
> Entering new SQLDatabaseChain chain...
How many employees are there?
SQLQuery:SELECT COUNT(*) FROM "Employee";
SQLResult: [(8,)]
Answer:There are 8 employees.
> Finished chain.
'There are 8 employees.'
Note that this both creates and executes the query.
In the following sections, we will cover the 3 different use cases mentioned in the overview.
Go deeper
You can load tabular data from other sources other than SQL Databases. For example: - Loading a CSV file - Loading a Pandas DataFrame Here you can check full list of Document Loaders
Case 1: Text-to-SQL query
from langchain.chains import create_sql_query_chain
from langchain_openai import ChatOpenAI
Let’s create the chain that will build the SQL Query:
chain = create_sql_query_chain(ChatOpenAI(temperature=0), db)
response = chain.invoke({"question": "How many employees are there"})
print(response)
SELECT COUNT(*) FROM Employee
After building the SQL query based on a user question, we can execute the query:
db.run(response)
'[(8,)]'
As we can see, the SQL Query Builder chain only created the query, and we handled the query execution separately.
Go deeper
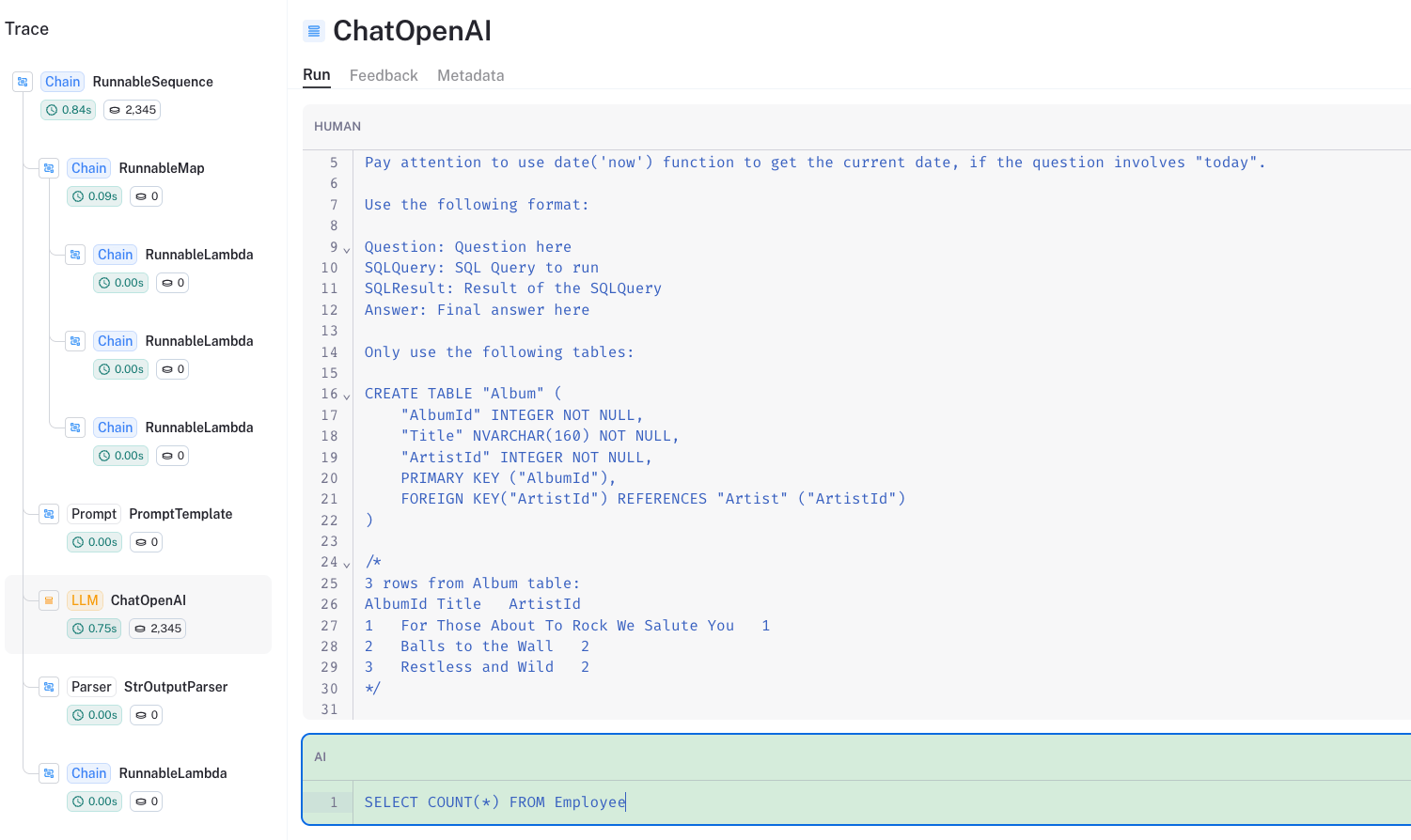
Looking under the hood
We can look at the LangSmith trace to unpack this:
Some papers have reported good performance when prompting with:
- A
CREATE TABLEdescription for each table, which include column names, their types, etc - Followed by three example rows in a
SELECTstatement
create_sql_query_chain adopts this the best practice (see more in this
blog).
Improvements
The query builder can be improved in several ways, such as (but not limited to):
- Customizing database description to your specific use case
- Hardcoding a few examples of questions and their corresponding SQL query in the prompt
- Using a vector database to include dynamic examples that are relevant to the specific user question
All these examples involve customizing the chain’s prompt.
For example, we can include a few examples in our prompt like so:
from langchain.prompts import PromptTemplate
TEMPLATE = """Given an input question, first create a syntactically correct {dialect} query to run, then look at the results of the query and return the answer.
Use the following format:
Question: "Question here"
SQLQuery: "SQL Query to run"
SQLResult: "Result of the SQLQuery"
Answer: "Final answer here"
Only use the following tables:
{table_info}.
Some examples of SQL queries that correspond to questions are:
{few_shot_examples}
Question: {input}"""
CUSTOM_PROMPT = PromptTemplate(
input_variables=["input", "few_shot_examples", "table_info", "dialect"],
template=TEMPLATE,
)
We can also access this prompt in the LangChain prompt hub.
This will work with your LangSmith API key.
from langchain import hub
CUSTOM_PROMPT = hub.pull("rlm/text-to-sql")
Case 2: Text-to-SQL query and execution
We can use SQLDatabaseChain from langchain_experimental to create
and run SQL queries.
from langchain_experimental.sql import SQLDatabaseChain
from langchain_openai import OpenAI
llm = OpenAI(temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
db_chain.run("How many employees are there?")
> Entering new SQLDatabaseChain chain...
How many employees are there?
SQLQuery:SELECT COUNT(*) FROM "Employee";
SQLResult: [(8,)]
Answer:There are 8 employees.
> Finished chain.
'There are 8 employees.'
As we can see, we get the same result as the previous case.
Here, the chain also handles the query execution and provides a final answer based on the user question and the query result.
Be careful while using this approach as it is susceptible to
SQL Injection:
- The chain is executing queries that are created by an LLM, and weren’t validated
- e.g. records may be created, modified or deleted unintentionally_
This is why we see the SQLDatabaseChain is inside
langchain_experimental.
Go deeper
Looking under the hood
We can use the LangSmith trace to see what is happening under the hood:
- As discussed above, first we create the query:
text: ' SELECT COUNT(*) FROM "Employee";'
- Then, it executes the query and passes the results to an LLM for synthesis.

Improvements
The performance of the SQLDatabaseChain can be enhanced in several
ways:
- Adding sample rows
- Specifying custom table information
- Using Query
Checker
self-correct invalid SQL using parameter
use_query_checker=True - Customizing the LLM
Prompt include
specific instructions or relevant information, using parameter
prompt=CUSTOM_PROMPT - Get intermediate
steps
access the SQL statement as well as the final result using parameter
return_intermediate_steps=True - Limit the number of
rows
a query will return using parameter
top_k=5
You might find SQLDatabaseSequentialChain useful for cases in which the number of tables in the database is large.
This Sequential Chain handles the process of:
- Determining which tables to use based on the user question
- Calling the normal SQL database chain using only relevant tables
Adding Sample Rows
Providing sample data can help the LLM construct correct queries when the data format is not obvious.
For example, we can tell LLM that artists are saved with their full names by providing two rows from the Track table.
db = SQLDatabase.from_uri(
"sqlite:///Chinook.db",
include_tables=[
"Track"
], # we include only one table to save tokens in the prompt :)
sample_rows_in_table_info=2,
)
The sample rows are added to the prompt after each corresponding table’s column information.
We can use db.table_info and check which sample rows are included:
print(db.table_info)
CREATE TABLE "Track" (
"TrackId" INTEGER NOT NULL,
"Name" NVARCHAR(200) NOT NULL,
"AlbumId" INTEGER,
"MediaTypeId" INTEGER NOT NULL,
"GenreId" INTEGER,
"Composer" NVARCHAR(220),
"Milliseconds" INTEGER NOT NULL,
"Bytes" INTEGER,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("TrackId"),
FOREIGN KEY("MediaTypeId") REFERENCES "MediaType" ("MediaTypeId"),
FOREIGN KEY("GenreId") REFERENCES "Genre" ("GenreId"),
FOREIGN KEY("AlbumId") REFERENCES "Album" ("AlbumId")
)
/*
2 rows from Track table:
TrackId Name AlbumId MediaTypeId GenreId Composer Milliseconds Bytes UnitPrice
1 For Those About To Rock (We Salute You) 1 1 1 Angus Young, Malcolm Young, Brian Johnson 343719 11170334 0.99
2 Balls to the Wall 2 2 1 None 342562 5510424 0.99
*/
Case 3: SQL agents
LangChain has an SQL Agent which provides a more flexible way of
interacting with SQL Databases than the SQLDatabaseChain.
The main advantages of using the SQL Agent are:
- It can answer questions based on the databases’ schema as well as on the databases’ content (like describing a specific table)
- It can recover from errors by running a generated query, catching the traceback and regenerating it correctly
To initialize the agent, we use create_sql_agent function.
This agent contains the SQLDatabaseToolkit which contains tools to:
- Create and execute queries
- Check query syntax
- Retrieve table descriptions
- … and more
from langchain.agents import create_sql_agent
# from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain_community.agent_toolkits import SQLDatabaseToolkit
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)),
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
Agent task example #1 - Running queries
agent_executor.run(
"List the total sales per country. Which country's customers spent the most?"
)
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input:
Observation: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Thought: I should query the schema of the Invoice and Customer tables.
Action: sql_db_schema
Action Input: Invoice, Customer
Observation:
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2009-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2009-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2009-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
Thought: I should query the total sales per country.
Action: sql_db_query
Action Input: SELECT Country, SUM(Total) AS TotalSales FROM Invoice INNER JOIN Customer ON Invoice.CustomerId = Customer.CustomerId GROUP BY Country ORDER BY TotalSales DESC LIMIT 10
Observation: [('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62)]
Thought: I now know the final answer
Final Answer: The country with the highest total sales is the USA, with a total of $523.06.
> Finished chain.
'The country with the highest total sales is the USA, with a total of $523.06.'
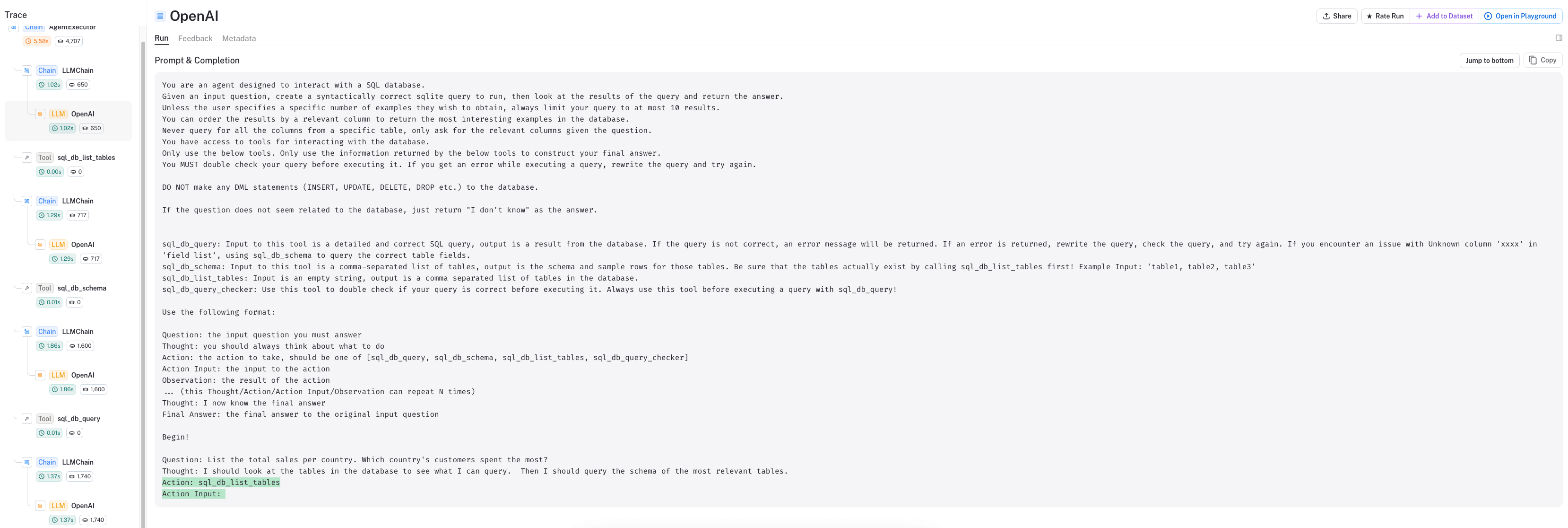
Looking at the LangSmith trace, we can see:
- The agent is using a ReAct style prompt
- First, it will look at the tables:
Action: sql_db_list_tablesusing toolsql_db_list_tables - Given the tables as an observation, it
thinksand then determinates the nextaction:
Observation: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Thought: I should query the schema of the Invoice and Customer tables.
Action: sql_db_schema
Action Input: Invoice, Customer
- It then formulates the query using the schema from tool
sql_db_schema
Thought: I should query the total sales per country.
Action: sql_db_query
Action Input: SELECT Country, SUM(Total) AS TotalSales FROM Invoice INNER JOIN Customer ON Invoice.CustomerId = Customer.CustomerId GROUP BY Country ORDER BY TotalSales DESC LIMIT 10
- It finally executes the generated query using tool
sql_db_query
Agent task example #2 - Describing a Table
agent_executor.run("Describe the playlisttrack table")
> Entering new AgentExecutor chain...
Action: sql_db_list_tables
Action Input:
Observation: Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Thought: The PlaylistTrack table is the most relevant to the question.
Action: sql_db_schema
Action Input: PlaylistTrack
Observation:
CREATE TABLE "PlaylistTrack" (
"PlaylistId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
PRIMARY KEY ("PlaylistId", "TrackId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("PlaylistId") REFERENCES "Playlist" ("PlaylistId")
)
/*
3 rows from PlaylistTrack table:
PlaylistId TrackId
1 3402
1 3389
1 3390
*/
Thought: I now know the final answer
Final Answer: The PlaylistTrack table contains two columns, PlaylistId and TrackId, which are both integers and form a primary key. It also has two foreign keys, one to the Track table and one to the Playlist table.
> Finished chain.
'The PlaylistTrack table contains two columns, PlaylistId and TrackId, which are both integers and form a primary key. It also has two foreign keys, one to the Track table and one to the Playlist table.'
Extending the SQL Toolkit
Although the out-of-the-box SQL Toolkit contains the necessary tools to start working on a database, it is often the case that some extra tools may be useful for extending the agent’s capabilities. This is particularly useful when trying to use domain specific knowledge in the solution, in order to improve its overall performance.
Some examples include:
- Including dynamic few shot examples
- Finding misspellings in proper nouns to use as column filters
We can create separate tools which tackle these specific use cases and include them as a complement to the standard SQL Toolkit. Let’s see how to include these two custom tools.
Including dynamic few-shot examples
In order to include dynamic few-shot examples, we need a custom Retriever Tool that handles the vector database in order to retrieve the examples that are semantically similar to the user’s question.
Let’s start by creating a dictionary with some examples:
few_shots = {
"List all artists.": "SELECT * FROM artists;",
"Find all albums for the artist 'AC/DC'.": "SELECT * FROM albums WHERE ArtistId = (SELECT ArtistId FROM artists WHERE Name = 'AC/DC');",
"List all tracks in the 'Rock' genre.": "SELECT * FROM tracks WHERE GenreId = (SELECT GenreId FROM genres WHERE Name = 'Rock');",
"Find the total duration of all tracks.": "SELECT SUM(Milliseconds) FROM tracks;",
"List all customers from Canada.": "SELECT * FROM customers WHERE Country = 'Canada';",
"How many tracks are there in the album with ID 5?": "SELECT COUNT(*) FROM tracks WHERE AlbumId = 5;",
"Find the total number of invoices.": "SELECT COUNT(*) FROM invoices;",
"List all tracks that are longer than 5 minutes.": "SELECT * FROM tracks WHERE Milliseconds > 300000;",
"Who are the top 5 customers by total purchase?": "SELECT CustomerId, SUM(Total) AS TotalPurchase FROM invoices GROUP BY CustomerId ORDER BY TotalPurchase DESC LIMIT 5;",
"Which albums are from the year 2000?": "SELECT * FROM albums WHERE strftime('%Y', ReleaseDate) = '2000';",
"How many employees are there": 'SELECT COUNT(*) FROM "employee"',
}
We can then create a retriever using the list of questions, assigning the target SQL query as metadata:
from langchain.schema import Document
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
few_shot_docs = [
Document(page_content=question, metadata={"sql_query": few_shots[question]})
for question in few_shots.keys()
]
vector_db = FAISS.from_documents(few_shot_docs, embeddings)
retriever = vector_db.as_retriever()
Now we can create our own custom tool and append it as a new tool in the
create_sql_agent function:
from langchain_community.agent_toolkits import create_retriever_tool
tool_description = """
This tool will help you understand similar examples to adapt them to the user question.
Input to this tool should be the user question.
"""
retriever_tool = create_retriever_tool(
retriever, name="sql_get_similar_examples", description=tool_description
)
custom_tool_list = [retriever_tool]
Now we can create the agent, adjusting the standard SQL Agent suffix to
consider our use case. Although the most straightforward way to handle
this would be to include it just in the tool description, this is often
not enough and we need to specify it in the agent prompt using the
suffix argument in the constructor.
from langchain.agents import AgentType, create_sql_agent
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.utilities import SQLDatabase
from langchain_openai import ChatOpenAI
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
custom_suffix = """
I should first get the similar examples I know.
If the examples are enough to construct the query, I can build it.
Otherwise, I can then look at the tables in the database to see what I can query.
Then I should query the schema of the most relevant tables
"""
agent = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
extra_tools=custom_tool_list,
suffix=custom_suffix,
)
Let’s try it out:
agent.run("How many employees do we have?")
> Entering new AgentExecutor chain...
Invoking: `sql_get_similar_examples` with `How many employees do we have?`
[Document(page_content='How many employees are there', metadata={'sql_query': 'SELECT COUNT(*) FROM "employee"'}), Document(page_content='Find the total number of invoices.', metadata={'sql_query': 'SELECT COUNT(*) FROM invoices;'})]
Invoking: `sql_db_query_checker` with `SELECT COUNT(*) FROM employee`
responded: {content}
SELECT COUNT(*) FROM employee
Invoking: `sql_db_query` with `SELECT COUNT(*) FROM employee`
[(8,)]We have 8 employees.
> Finished chain.
'We have 8 employees.'
As we can see, the agent first used the sql_get_similar_examples tool
in order to retrieve similar examples. As the question was very similar
to other few shot examples, the agent didn’t need to use any other
tool from the standard Toolkit, thus saving time and tokens.
Finding and correcting misspellings for proper nouns
In order to filter columns that contain proper nouns such as addresses, song names or artists, we first need to double-check the spelling in order to filter the data correctly.
We can achieve this by creating a vector store using all the distinct proper nouns that exist in the database. We can then have the agent query that vector store each time the user includes a proper noun in their question, to find the correct spelling for that word. In this way, the agent can make sure it understands which entity the user is referring to before building the target query.
Let’s follow a similar approach to the few shots, but without metadata: just embedding the proper nouns and then querying to get the most similar one to the misspelled user question.
First we need the unique values for each entity we want, for which we define a function that parses the result into a list of elements:
import ast
import re
def run_query_save_results(db, query):
res = db.run(query)
res = [el for sub in ast.literal_eval(res) for el in sub if el]
res = [re.sub(r"\b\d+\b", "", string).strip() for string in res]
return res
artists = run_query_save_results(db, "SELECT Name FROM Artist")
albums = run_query_save_results(db, "SELECT Title FROM Album")
Now we can proceed with creating the custom retriever tool and the final agent:
from langchain_community.agent_toolkits import create_retriever_tool
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
texts = artists + albums
embeddings = OpenAIEmbeddings()
vector_db = FAISS.from_texts(texts, embeddings)
retriever = vector_db.as_retriever()
retriever_tool = create_retriever_tool(
retriever,
name="name_search",
description="use to learn how a piece of data is actually written, can be from names, surnames addresses etc",
)
custom_tool_list = [retriever_tool]
from langchain.agents import AgentType, create_sql_agent
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.utilities import SQLDatabase
from langchain_openai import ChatOpenAI
# db = SQLDatabase.from_uri("sqlite:///Chinook.db")
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
custom_suffix = """
If a user asks for me to filter based on proper nouns, I should first check the spelling using the name_search tool.
Otherwise, I can then look at the tables in the database to see what I can query.
Then I should query the schema of the most relevant tables
"""
agent = create_sql_agent(
llm=llm,
toolkit=toolkit,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
extra_tools=custom_tool_list,
suffix=custom_suffix,
)
Let’s try it out:
agent.run("How many albums does alis in pains have?")
> Entering new AgentExecutor chain...
Invoking: `name_search` with `alis in pains`
[Document(page_content='House of Pain', metadata={}), Document(page_content='Alice In Chains', metadata={}), Document(page_content='Aisha Duo', metadata={}), Document(page_content='House Of Pain', metadata={})]
Invoking: `sql_db_list_tables` with ``
responded: {content}
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Invoking: `sql_db_schema` with `Album, Artist`
responded: {content}
CREATE TABLE "Album" (
"AlbumId" INTEGER NOT NULL,
"Title" NVARCHAR(160) NOT NULL,
"ArtistId" INTEGER NOT NULL,
PRIMARY KEY ("AlbumId"),
FOREIGN KEY("ArtistId") REFERENCES "Artist" ("ArtistId")
)
/*
3 rows from Album table:
AlbumId Title ArtistId
1 For Those About To Rock We Salute You 1
2 Balls to the Wall 2
3 Restless and Wild 2
*/
CREATE TABLE "Artist" (
"ArtistId" INTEGER NOT NULL,
"Name" NVARCHAR(120),
PRIMARY KEY ("ArtistId")
)
/*
3 rows from Artist table:
ArtistId Name
1 AC/DC
2 Accept
3 Aerosmith
*/
Invoking: `sql_db_query_checker` with `SELECT COUNT(*) FROM Album JOIN Artist ON Album.ArtistId = Artist.ArtistId WHERE Artist.Name = 'Alice In Chains'`
responded: {content}
SELECT COUNT(*) FROM Album JOIN Artist ON Album.ArtistId = Artist.ArtistId WHERE Artist.Name = 'Alice In Chains'
Invoking: `sql_db_query` with `SELECT COUNT(*) FROM Album JOIN Artist ON Album.ArtistId = Artist.ArtistId WHERE Artist.Name = 'Alice In Chains'`
[(1,)]Alice In Chains has 1 album in the database.
> Finished chain.
'Alice In Chains has 1 album in the database.'
As we can see, the agent used the name_search tool in order to check
how to correctly query the database for this specific artist.
Go deeper
To learn more about the SQL Agent and how it works we refer to the SQL Agent Toolkit documentation.
You can also check Agents for other document types: - Pandas Agent - CSV Agent
Elastic Search
Going beyond the above use-case, there are integrations with other databases.
For example, we can interact with Elasticsearch analytics database.
This chain builds search queries via the Elasticsearch DSL API (filters and aggregations).
The Elasticsearch client must have permissions for index listing, mapping description and search queries.
See here for instructions on how to run Elasticsearch locally.
Make sure to install the Elasticsearch Python client before:
pip install elasticsearch
from elasticsearch import Elasticsearch
from langchain.chains.elasticsearch_database import ElasticsearchDatabaseChain
from langchain_openai import ChatOpenAI
# Initialize Elasticsearch python client.
# See https://elasticsearch-py.readthedocs.io/en/v8.8.2/api.html#elasticsearch.Elasticsearch
ELASTIC_SEARCH_SERVER = "https://elastic:pass@localhost:9200"
db = Elasticsearch(ELASTIC_SEARCH_SERVER)
Uncomment the next cell to initially populate your db.
# customers = [
# {"firstname": "Jennifer", "lastname": "Walters"},
# {"firstname": "Monica","lastname":"Rambeau"},
# {"firstname": "Carol","lastname":"Danvers"},
# {"firstname": "Wanda","lastname":"Maximoff"},
# {"firstname": "Jennifer","lastname":"Takeda"},
# ]
# for i, customer in enumerate(customers):
# db.create(index="customers", document=customer, id=i)
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
chain = ElasticsearchDatabaseChain.from_llm(llm=llm, database=db, verbose=True)
question = "What are the first names of all the customers?"
chain.run(question)
We can customize the prompt.
from langchain.prompts.prompt import PromptTemplate
PROMPT_TEMPLATE = """Given an input question, create a syntactically correct Elasticsearch query to run. Unless the user specifies in their question a specific number of examples they wish to obtain, always limit your query to at most {top_k} results. You can order the results by a relevant column to return the most interesting examples in the database.
Unless told to do not query for all the columns from a specific index, only ask for a the few relevant columns given the question.
Pay attention to use only the column names that you can see in the mapping description. Be careful to not query for columns that do not exist. Also, pay attention to which column is in which index. Return the query as valid json.
Use the following format:
Question: Question here
ESQuery: Elasticsearch Query formatted as json
"""
PROMPT = PromptTemplate.from_template(
PROMPT_TEMPLATE,
)
chain = ElasticsearchDatabaseChain.from_llm(llm=llm, database=db, query_prompt=PROMPT)