Chatbots
![]()
Open In Colab
Use case
Chatbots are one of the central LLM use-cases. The core features of chatbots are that they can have long-running conversations and have access to information that users want to know about.
Aside from basic prompting and LLMs, memory and retrieval are the core components of a chatbot. Memory allows a chatbot to remember past interactions, and retrieval provides a chatbot with up-to-date, domain-specific information.
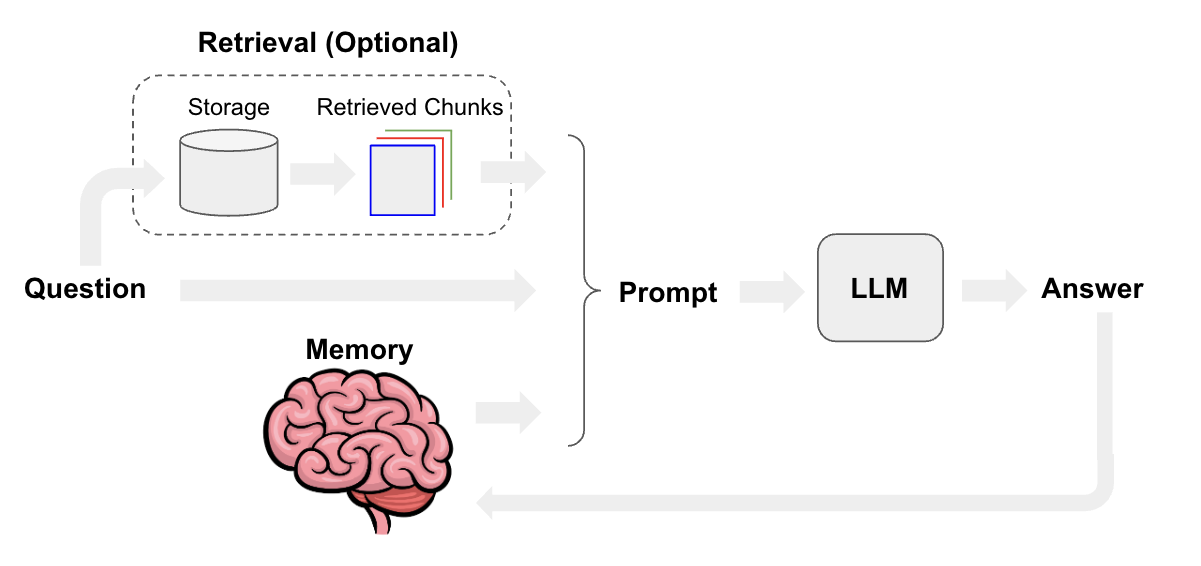
Overview
The chat model interface is based around messages rather than raw text. Several components are important to consider for chat:
chat model: See here for a list of chat model integrations and here for documentation on the chat model interface in LangChain. You can useLLMs(see here) for chatbots as well, but chat models have a more conversational tone and natively support a message interface.prompt template: Prompt templates make it easy to assemble prompts that combine default messages, user input, chat history, and (optionally) additional retrieved context.memory: See here for in-depth documentation on memory typesretriever(optional): See here for in-depth documentation on retrieval systems. These are useful if you want to build a chatbot with domain-specific knowledge.
Quickstart
Here’s a quick preview of how we can create chatbot interfaces. First let’s install some dependencies and set the required credentials:
!pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv()
With a plain chat model, we can get chat completions by passing one or more messages to the model.
The chat model will respond with a message.
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
chat = ChatOpenAI()
chat(
[
HumanMessage(
content="Translate this sentence from English to French: I love programming."
)
]
)
AIMessage(content="J'adore la programmation.", additional_kwargs={}, example=False)
And if we pass in a list of messages:
messages = [
SystemMessage(
content="You are a helpful assistant that translates English to French."
),
HumanMessage(content="I love programming."),
]
chat(messages)
AIMessage(content="J'adore la programmation.", additional_kwargs={}, example=False)
We can then wrap our chat model in a ConversationChain, which has
built-in memory for remembering past user inputs and model outputs.
from langchain.chains import ConversationChain
conversation = ConversationChain(llm=chat)
conversation.run("Translate this sentence from English to French: I love programming.")
'Je adore la programmation.'
conversation.run("Translate it to German.")
'Ich liebe Programmieren.'
Memory
As we mentioned above, the core component of chatbots is the memory
system. One of the simplest and most commonly used forms of memory is
ConversationBufferMemory:
- This memory allows for storing of messages in a
buffer - When called in a chain, it returns all of the messages it has stored
LangChain comes with many other types of memory, too. See here for in-depth documentation on memory types.
For now let’s take a quick look at ConversationBufferMemory. We can manually add a few chat messages to the memory like so:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
And now we can load from our memory. The key method exposed by all
Memory classes is load_memory_variables. This takes in any initial
chain input and returns a list of memory variables which are added to
the chain input.
Since this simple memory type doesn’t actually take into account the chain input when loading memory, we can pass in an empty input for now:
memory.load_memory_variables({})
{'history': 'Human: hi!\nAI: whats up?'}
We can also keep a sliding window of the most recent k interactions
using ConversationBufferWindowMemory.
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({})
{'history': 'Human: not much you\nAI: not much'}
ConversationSummaryMemory is an extension of this theme.
It creates a summary of the conversation over time.
This memory is most useful for longer conversations where the full message history would consume many tokens.
from langchain.memory import ConversationSummaryMemory
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context(
{"input": "im working on better docs for chatbots"},
{"output": "oh, that sounds like a lot of work"},
)
memory.save_context(
{"input": "yes, but it's worth the effort"},
{"output": "agreed, good docs are important!"},
)
memory.load_memory_variables({})
{'history': '\nThe human greets the AI, to which the AI responds. The human then mentions they are working on better docs for chatbots, to which the AI responds that it sounds like a lot of work. The human agrees that it is worth the effort, and the AI agrees that good docs are important.'}
ConversationSummaryBufferMemory extends this a bit further:
It uses token length rather than number of interactions to determine when to flush interactions.
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
Conversation
We can unpack what goes under the hood with ConversationChain.
We can specify our memory, ConversationSummaryMemory and we can
specify the prompt.
from langchain.chains import LLMChain
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
)
# LLM
llm = ChatOpenAI()
# Prompt
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}"),
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation = LLMChain(llm=llm, prompt=prompt, verbose=True, memory=memory)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
conversation({"question": "hi"})
> Entering new LLMChain chain...
Prompt after formatting:
System: You are a nice chatbot having a conversation with a human.
Human: hi
> Finished chain.
{'question': 'hi',
'chat_history': [HumanMessage(content='hi', additional_kwargs={}, example=False),
AIMessage(content='Hello! How can I assist you today?', additional_kwargs={}, example=False)],
'text': 'Hello! How can I assist you today?'}
conversation(
{"question": "Translate this sentence from English to French: I love programming."}
)
> Entering new LLMChain chain...
Prompt after formatting:
System: You are a nice chatbot having a conversation with a human.
Human: hi
AI: Hello! How can I assist you today?
Human: Translate this sentence from English to French: I love programming.
> Finished chain.
{'question': 'Translate this sentence from English to French: I love programming.',
'chat_history': [HumanMessage(content='hi', additional_kwargs={}, example=False),
AIMessage(content='Hello! How can I assist you today?', additional_kwargs={}, example=False),
HumanMessage(content='Translate this sentence from English to French: I love programming.', additional_kwargs={}, example=False),
AIMessage(content='Sure! The translation of "I love programming" from English to French is "J\'adore programmer."', additional_kwargs={}, example=False)],
'text': 'Sure! The translation of "I love programming" from English to French is "J\'adore programmer."'}
conversation({"question": "Now translate the sentence to German."})
> Entering new LLMChain chain...
Prompt after formatting:
System: You are a nice chatbot having a conversation with a human.
Human: hi
AI: Hello! How can I assist you today?
Human: Translate this sentence from English to French: I love programming.
AI: Sure! The translation of "I love programming" from English to French is "J'adore programmer."
Human: Now translate the sentence to German.
> Finished chain.
{'question': 'Now translate the sentence to German.',
'chat_history': [HumanMessage(content='hi', additional_kwargs={}, example=False),
AIMessage(content='Hello! How can I assist you today?', additional_kwargs={}, example=False),
HumanMessage(content='Translate this sentence from English to French: I love programming.', additional_kwargs={}, example=False),
AIMessage(content='Sure! The translation of "I love programming" from English to French is "J\'adore programmer."', additional_kwargs={}, example=False),
HumanMessage(content='Now translate the sentence to German.', additional_kwargs={}, example=False),
AIMessage(content='Certainly! The translation of "I love programming" from English to German is "Ich liebe das Programmieren."', additional_kwargs={}, example=False)],
'text': 'Certainly! The translation of "I love programming" from English to German is "Ich liebe das Programmieren."'}
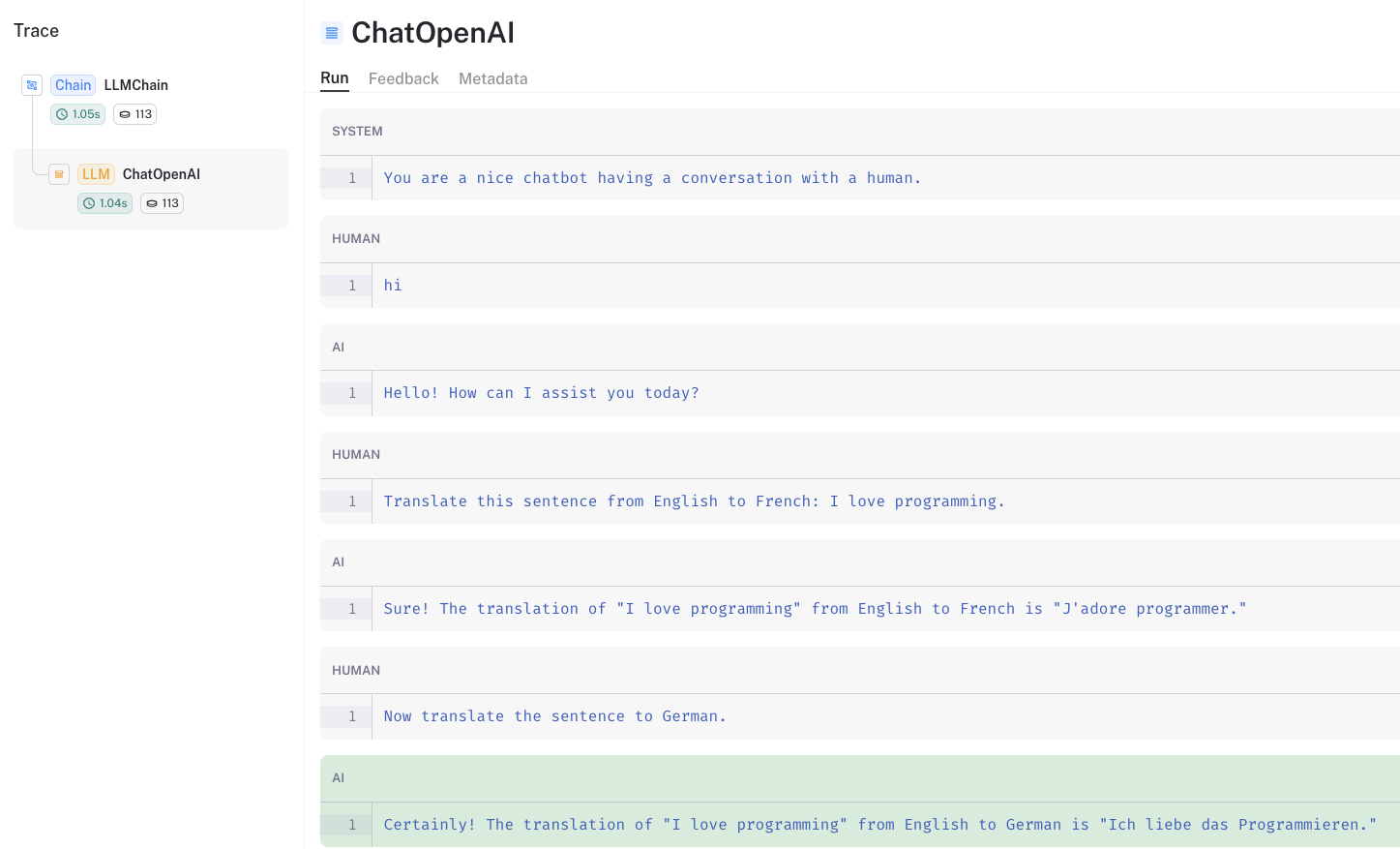
We can see the chat history preserved in the prompt using the LangSmith trace.
Chat Retrieval
Now, suppose we want to chat with documents or some other source of knowledge.
This is popular use case, combining chat with document retrieval.
It allows us to chat with specific information that the model was not trained on.
!pip install tiktoken chromadb
Load a blog post.
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
Split and store this in a vector.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
Create our memory, as before, but’s let’s use
ConversationSummaryMemory.
memory = ConversationSummaryMemory(
llm=llm, memory_key="chat_history", return_messages=True
)
from langchain.chains import ConversationalRetrievalChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
retriever = vectorstore.as_retriever()
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
qa("How do agents use Task decomposition?")
{'question': 'How do agents use Task decomposition?',
'chat_history': [SystemMessage(content='', additional_kwargs={})],
'answer': 'Agents can use task decomposition in several ways:\n\n1. Simple prompting: Agents can use Language Model based prompting to break down tasks into subgoals. For example, by providing prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?", the agent can generate a sequence of smaller steps that lead to the completion of the overall task.\n\n2. Task-specific instructions: Agents can be given task-specific instructions to guide their planning process. For example, if the task is to write a novel, the agent can be instructed to "Write a story outline." This provides a high-level structure for the task and helps in breaking it down into smaller components.\n\n3. Human inputs: Agents can also take inputs from humans to decompose tasks. This can be done through direct communication or by leveraging human expertise. Humans can provide guidance and insights to help the agent break down complex tasks into manageable subgoals.\n\nOverall, task decomposition allows agents to break down large tasks into smaller, more manageable subgoals, enabling them to plan and execute complex tasks efficiently.'}
qa("What are the various ways to implement memory to support it?")
{'question': 'What are the various ways to implement memory to support it?',
'chat_history': [SystemMessage(content='The human asks how agents use task decomposition. The AI explains that agents can use task decomposition in several ways, including simple prompting, task-specific instructions, and human inputs. Task decomposition allows agents to break down large tasks into smaller, more manageable subgoals, enabling them to plan and execute complex tasks efficiently.', additional_kwargs={})],
'answer': 'There are several ways to implement memory to support task decomposition:\n\n1. Long-Term Memory Management: This involves storing and organizing information in a long-term memory system. The agent can retrieve past experiences, knowledge, and learned strategies to guide the task decomposition process.\n\n2. Internet Access: The agent can use internet access to search for relevant information and gather resources to aid in task decomposition. This allows the agent to access a vast amount of information and utilize it in the decomposition process.\n\n3. GPT-3.5 Powered Agents: The agent can delegate simple tasks to GPT-3.5 powered agents. These agents can perform specific tasks or provide assistance in task decomposition, allowing the main agent to focus on higher-level planning and decision-making.\n\n4. File Output: The agent can store the results of task decomposition in files or documents. This allows for easy retrieval and reference during the execution of the task.\n\nThese memory resources help the agent in organizing and managing information, making informed decisions, and effectively decomposing complex tasks into smaller, manageable subgoals.'}
Again, we can use the LangSmith trace to explore the prompt structure.
Going deeper
- Agents, such as the conversational retrieval agent, can be used for retrieval when necessary while also holding a conversation.